Back in 1999, as a procrastination exercise while working on my Ph.D. in physics at UC Davis, I spent a couple hours on a Friday night writing out a fairly ineloquent form of the Standard Model Lagrangian density. I unpacked Appendix E in Diagrammatica by Nobel Laureate Martinus Veltman and complied it into one equation, making the pdf and LaTeX files accessible on my old website.
Since that time, this form of the Standard Model Lagrangian density has received some attention in Symmetry Magazine, TED (Brian Cox, “CERN’s Supercollider”), Wikipedia, and PBS Space Time (“The Equation That Explains (Nearly) Everything!”), amongst other places including artwork (by James De Villiers). Recently, Don Lincoln at Fermilab has also highlighted it on his popular YouTube channel.
Since 2006, I’ve been a professor of physics at Cal Poly, San Luis Obispo and, since I haven’t been at UC Davis for a while, and don’t have easy edit access to that content on my old site, I’m making the files available here on my personal page. This includes some long overdue corrections. Only the pdfs are available below, but I will make the LaTeX file available soon. Thanks to the many people who have contacted me over the past 25 years to provide feedback and discussion!
Number sequence puzzles are a problem solving staple. There are obvious ones, obscure ones, and famous ones like the Fibonacci sequence. I assert that given a few numbers (say 5 or 6) in a sequence and asked to identify “what is the next number?” there is a way to solve it that won’t generally involve the intended solution, but will nevertheless aways be right. But it is sort of cheating. No, take that back. It is cheating.
The trick is to find the (first appearance of the) sequence you seek in the digits of pi or any other transcendental number like e, phi, or pick your favorite. You can then read off the remaining digits using some convenient grouping to fill out the sequence to arbitrarily large values of necessary. Frequently, unless you have pi memorized to hundreds of thousands, millions, even billions of digits, this will require a program or online resource of some kind to find the sequence in the digits of pi.
Let’s do some examples. Take a few number series puzzles from dailybrainteaser one of many such fun puzzle sites:
What is the next number in this series?
6, 14, 36, 98, 276, ?
First, we look for the pattern 6143698276 in pi using, The Pi-Search Page, or Irrational Numbers Search Engine. The former does a fast, as you type, search over the first 200 million digits while the later does a deeper search out to 2 billion digits (these are just a couple of many sites available). As any small child can see, 6143698276 appears at the 1,962,082,153th digit of pi. A few of the digits after that look like: 614369827631848334. One can then casually claim something like: “the next number in the sequence 6, 14, 36, 98, 276 is 318 where 318 is (obviously) the next three digits after 6143698276 starting at the 1,962,082,153th digit of pi. Bam!” Mike drop. No argument.
As the given sequence gets longer, the less likely one will find the sequence in a transcendental search engine assuming such numbers are essentially a random distribution. For example, the sequence 6143698276 doesn’t occur in the first two billion digits of e or sqrt(2).
Here’s another:
What Comes next in sequence
1 , 4 , 5 , 6 , 7 , 9 , 11 ?
This one’s easy because it is relatively short. The pattern 14567911 appears at the 64,362,285th digit of pi. The few digits after it are 1456791122892. So, with great confidence, you can say “the sequence is obviously 1, 4, 5, 6, 7, 9, 11, 22.” Repeat argument above. End conversation awkwardly.
I appreciate this is quite gimmick-y. One can invent any number of arbitrary solutions to these sequence puzzles. Even for this approach, there will be multiple perfectly correct solutions, even just using pi alone. For example, in our second example above, 14567911 appears an infinite number of times in pi. Puzzles of this kind optimally involve a very specific elegant solution that uses your Puzzler. Nevertheless, this approach is amusing for the first couple times, lets you get your geek out, and can at least temporarily distract family and friends while you really try to solve the puzzle.
How can you visualize a 4th spatial dimension? There has been much written and discussed on this topic; I won’t pretend that this post will compete with the vast resources available online. However, I do feel that I can contribute one small visualization trick for hypercubes that, for some reason, has not been emphasized very much elsewhere (although it is out there), which helped me get a foothold into the situation.
My first exposure as a kid to the topic of visualizing higher dimensions was given by Carl Sagan on the original Cosmos. In it, he introduces a hypercube called a tesseract:
While Cosmos is an inspirational introduction, it isn’t very complete. Still, there are many great resources on the web to help appreciate and understand the tesseract on many levels from rotations to inversions and beyond. They are part of a larger class of very cool objects known as polytopes. You are one google search away from vast resources on this topic. I won’t even bother compiling links.
What I hope to accomplish is to give you an intellectual foothold into the visualization, which will help considerably as you delve further into the topic.
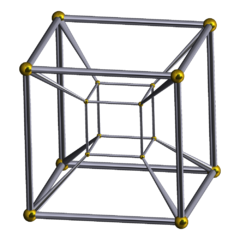
In what sense is this object a hypercube? Well, strictly speaking, this object is not a tesseract or hypercube. Technically, it is a two-dimensional projection (i.e. it is on this web page) of a three-dimensional shadow (the wire frame object if it were in 3D) of a 4D hypercube.
But how exactly can this object help us see into a 4th spatial dimension? Here is a visualization trick I’ve found most helpful for me:
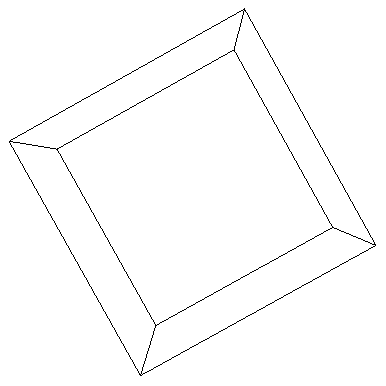
Let’s start with something familiar. I can draw two parallelograms, one larger than the other, then connect the corresponding vertices. One’s mind will quickly interpret this as a cube as viewed from some angle, although it is just a two dimensional thing on a page. Your mind naturally views the (slightly) smaller parallelogram as being the same actual size as the larger one. It just looks smaller because we interpret it as farther away, thanks to perspective. Furthermore, all the angles, although drawn otherwise, are interpreted as right angles. The description makes it sound more complex than it is; it is just the representation of an ordinary cube viewed from some angle outside the page:
In the drawing, the parallelograms are almost the same size, so it is easy to flip back and forth between which one is the “front” face and which is the “back” face, generating weird distortions if it is viewed “incorrectly.”
Now, I rotate the cube so we are looking directly down one face. Think of this drawing as looking down a crude wirefame corridor:
However, on the page it is really just two nested squares with connected vertices. Still, one’s brain fills in the three dimensional details pretty naturally. Viewed this way, the smaller square is just further away and the angles are all right angles. If the smaller square were made smaller, even going to a point, you could imagine that the end of the corridor was just very far away.
The tesseract projection really is not really much different:
The visualization tool to remember is that the smaller cube only looks smaller because of perspective: the two cubes are actually the same size but the smaller cube only looks smaller because it is farther away. Further away in what direction? Into a 4th spatial dimension! When looking at the tesseract projection, think of it as looking “down” a kind of wireframe corridor directed such that the farthest point is actually at the mutual center of the cubes. This is the same sense that an ordinary long corridor drawn in two dimensions would have the far point (at infinity) located at the center of the squares. This mutual center is then interpreted as pointing in a direction not in ordinary three dimensional space; indeed, all six faces of the larger cube look “down” this corridor toward the other end. If you had such a hypercube in your living room, each of the six faces would act as a separate corridor directed towards the far point in a fourth spatial dimension. If your friend walked into the cube and continued down the corridor, they would not exit on the other side of the cube in your living room but rather would get smaller and smaller walking toward the center of the cube.
If you were the one doing the walking, it would be just like walking down a corridor into another room, albeit one that was entirely embedded — from all directions — within another one in three dimensions.
This is basically the idea behind Dr. Who’s tardis, as explained by the Doctor himself (although in his usual curt and opaque way):
You could think of the outer cube a crude 2 x 2 x 2 meter exterior to a tardis. The inner cube might be a 2 x 2 x 2 meter room inside the tardis (the same shape as the outside) 2 meters away into the 4th dimension. However, the tardis isn’t a mere hypercube. It has rooms inside that are bigger than the outside of the tardis. But to get them to fit inside the outer cube, you just put them farther away into the extra dimension. That is, you can visualize the inner cube as being a 100 x 100 x 100 meter room inside a 2 x 2 x 2 meter exterior box — except imagine you are 1000 meters away looking “down” the corridor of the 4th dimension, so the giant room looks small and thus fits fine into the exterior. This is exactly the point the Doctor is trying to make in the clip.
This idea was also a part of the plot of Stranger in a Strange Land by Heinlein. Valentine Michael Smith can make things vanish into a fourth dimension. The effect, as viewed by all observers in our own three dimensions, is to see the object get smaller and smaller from all angles until it vanishes. This is akin to walking down the corridor of the tesseract towards the center. The object appears to get smaller only because it is further away in this other direction outside of our usual three.
In my opinion, visualizing the tesseract as looking down a corridor into another spatial dimension with added perspective is the best first step in appreciating higher dimensional thinking. Here is a neat looking game that emphasizes the perspective approach and gives some practical practice with these ideas.
Hope you enjoy the new Agapanthus video for the song SmuggyE off of the 2012 Smug album! This is one of the tunes that uses transcendental numbers and a little Mathematica for creative inspiration.
[iframe width=”420″ height=”315″ src=”http://www.youtube.com/embed/oSXB6Xs81EE” frameborder=”0″ allowfullscreen]
An unpublished paper on the arXiv is claiming to have formulated a suite of experiments, as informed by a particular kind of computer approximation (called “lattice QCD” or L-QCD), to determine if the universe we perceive is really just an elaborate computer simulation. It is creating a buzz (e.g. covered by the Skeptics Guide to the Universe, Technology Review, io9, and probably elsewhere).
I have some problems with the paper’s line of argument. But let me make it clear that I have no fundamental problem with the speculation itself. I think it is a fun and interesting to ponder the possibility of living in a simulation and to try and formulate experiments to demonstrate it. It is certainly an amusing intellectual exercise and, at least in my own experience, this was an occasional topic of my undergraduate years. More recently than my undergraduate years, Yale philosopher Nick Bostrom put forth this famous arguments in more quasiformal terms, but the idea had been hovering there (probably with a Pink Floyd soundtrack) for a long time.
The paper is not “crackpot”, but is highly speculative. It uses a legitimate argumentation technique, if used properly (and the authors basically do), called reductio ad absurdum: reduction to the absurd. Their argument goes like this:
Computer simulations of spacetime dynamics, as known to humans, always involve space and time lattices as a stage to perform dynamical approximations (e.g. finite difference methods etc.);
Lattice QCD (L-QCD) is a profound example of how (mere) humans have successfully simulated, on a lattice, arguably the most complex and pure sector of the Standard Model: SU(3) color, a.k.a. quantum chromodynamics, the gauge theory that governs the strong nuclear force as experienced by quarks and gluons;
L-QCD is not perfect, and is still quite crude in its absolute modern capabilities (I think most people reading these articles, given the hype imparted to L-QCD, would be shocked at how underwhelming L-QCD output actually is, given the extreme amount of computing effort and physics that goes into it). But it is, under the hood, the most physically complete of all computer simulations and should be taken as a proof-of-principle for the hypothetical possibility of bigger and better simulations — if we can do it, even at our humble scale, certainly an übersimulation should be possible with sufficient computing resources;
Extrapolating (this is the reductio ad absurdum part), L-QCD for us today implies L-Reality for some other beyond-our-imagination hypercreatures: for we are not to be taken as a special case for what is possible and we got quite a late start into the game as far as this sentience thing goes.
Nevertheless, nuanced flaws in the simulation that arise because of the intrinsic latticeworks required by the approximations might be experimentally detectable.
Cute.
Firstly, there is an amusing recursive metacognative aspect to this discussion that has its own strangeness; it essentially causes the discussion to implode. It is a goddamn hall of mirrors from a hypothesis testing point of view. This was, I believe, the point Steve Novella was getting at in the SGU discussion. So, let’s set aside the question of whether a simulation could
accurately reconstruct a simulation of itself and then
proceed to simulate and predict its own real errors and then
simulate the actual detection and accurate measurement of the unsimulated real errors.
Follow that? For the byproduct of a simulation to detect that it is part of an ongoing simulation via the artifacts of the main simulation, I think you have to have something like that. I’m not saying it’s not possible, but it is pretty unintuitive and recursive.
My main problem with the argument is this: a discrete or lattice-like character to spacetime, with all of its strange implications, is neither a necessary nor sufficient condition to conclude we live in a simulation. What it would tell us, if it were to be identified experimentally, is that: spacetime has a discrete or lattice-like character. Given the remarkably creative and far-seeing imaginative spirit of the project, it seems strangely naive to use such an immature, vague “simulation = discrete” connection to form a serious hypothesis. There very well may be some way to demonstrate we live in a simulation (or, phrased more responsibly, falsify the hypothesis that we don’t live in a simulation), but identifying a lattice-like spacetime structure is not the way. What would be the difference between a simulation and the “real” thing. Basically, a simulation would make error or have inexplicable quirks that “reality” would not contain. The “lattice approximation errors” approach is pressing along these lines, but is disappointingly shallow.
The evidence for living in a simulation would have to be much more profound and unsubtle to be convincing than mere latticworks. Something like, somewhat in a tongue-and-cheek tone:
Identifying the equivalent of commented out lines of code or documentation. This might be a steganographic exercise where one looks for messages buried in the noise floor of fundamental constants, or perhaps the laws of physics itself. For example, finding patterns in π sounds like a good lead, a la Contact, but literally everything is in π an infinite number of times, so one needs another strategy like perhaps π lacking certain statistical patterns. If the string 1111 didn’t appear in π at any point we could calculate, this would be stranger than finding “to be or not to be” from Hamlet in ASCII binary;
Finding software bugs (not just approximation errors); this might appear as inconsistencies in the laws of physics at different periods of time;
Finding dead pixels or places where the hardware just stopped working locally; this might look like a place where the laws of physics spontaneously changed or failed (e.g. not a black hole where there is a known mechanism for the breakdown, but something like “psychics are real”, “prayer works as advertised”, etc.);
I’m just making stuff up, and don’t really believe these efforts would bear fruit, but those kinds of thing, if demonstrated in a convincing way, would be an indication to me that something just wasn’t right. That said, the laws of physics are remarkably robust: there are no known violations of them (or nothing that hasn’t been able to be incorporated into them) despite vigorous testing and active efforts to find flaws.
I would also like to set a concept straight that I heard come up in the SGU discussion: the quantum theoretical notion of the Planck length does not imply any intrinsic clumpiness or discreteness to spacetime, although it is sometimes framed this way in casual physics discussions. The Planck length is the spatial scale where quantum mechanics encounters general relativity in an unavoidable way. In some sense, current formulations of quantum theory and general relativity “predict” the breakdown of spacetime itself at this scale. But, in the usual interpretation, this is just telling us that both theories as they are currently formulated cannot be correct at that scale, which we already hypothesized decades ago — indeed this is the point of the entire project of M-theory/Loop quantum gravity and its derivatives.
Moreover, even working within known quantum theory and general relativity, to consider the Planck length a “clump” or “smallest unit” of spacetime is not the correct visualization. The Planck length sets a scale of uncertainty. The word “scale” in physics does not imply a hard, discrete boundary, but rather a very, very soft one. It is the opposite of a clump of spacetime. The Planck length is then interpreted as the geometric scale at which spacetime is infinitely fuzzy and statistically uncertain. It does not imply a hard little impenetrable region embedded in some abstract spacetime latticeworks. This breakdown of spacetime occurs at each continuous point in space. That is, one could zoom into any arbitrarily chosen point and observe the uncertainty emerge at the same scale. Again, no latticeworks or lumpiness is implied.
Ever wonder what π or e or other number sequences sound like when mapped into some musical sound space? I’ve written a little Mathematica Notebook, downloadable here, that lets you tinker with these possibilities with a simple interface. You can then save your work to a MIDI file which can then be loaded into your favorite music software like CuBase, Logic, Pro Tools, or even Garage Band. I would offer the full notebook as a free CDF file, but Wolfram’s current CDF format does not support writing out to files yet. However, below is the basic interface you can tinker with on this web page. You will need the free Mathematica CDF plugin installed (or a copy of Mathematica 8).
On my latest album, Smug, I use this software to create two pieces based on the trancendental number e and π. Descriptions below.
Smuggy E:
The first riff uses the first 15 digits of the transcendental number e=2.71828182845904 (0=C, 1=C#, 2=D etc.) in 15/16 time it then modulates so 0=F, 1=F#, 2=G
the interlude riff is the speed of light in vacuum c=299792458.0 m/s with (0=C, 1=C#, 2=D etc.) in 6/4. Yes, I cheated a little adding the “.0” on the end of c since, in m/s, c is defined as an exact integer.
Smuggy π:
Similar to above, uses the first 10 digits of pi and the speed of light with the mapping (0=C, 1=C#, 2=D etc.).
These are just a few of the literally infinite possibilities one can create using amusing number mappings. Let me know if you create (or have created) any of your own. I’d be interested to hear!